You are here
پس انتشار خطا به تمام گرههای مرتبط در لایههای قبل
تصویر زیر یک شبکه عصبی با سه لایه را نشان می دهد. لایه ورودی(input layer)، لایه پنهان(hidden layer) و لایه خروجی(output layer).
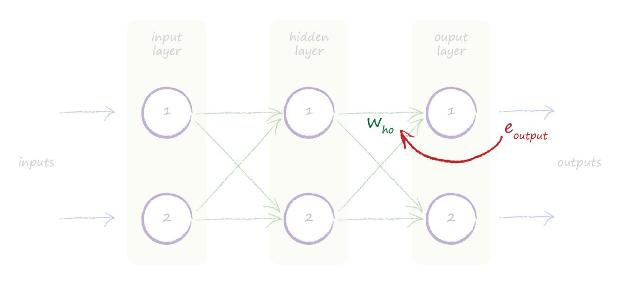
پیشتر ما از لایه خروجی از سمت راست شروع کردیم. ما دیدیم که از خطا های لایه خروجی استفاده کردیم برای اینکه وزن های اتصال های ورودی به هر گره در لایه آخر را بهبود دهیم.
ما خطا ی مقادیر خروجی را به نام eoutput نامگذاری کردیم. همینطور وزن های اتصال های بین لایه پنهان (hidden) و لایه خروجی(output) را با توجه به حرف اول اسم آن who نام گذاری کردیم. ما خطای مناسب با هر اتصال را با تقسیم خطا به میزان وزن هر اتصال نسبت دادیم.
با نمایش گرافیکی که در بالا داریم میتوانیم ببینم وقتی لایههای بیشتری داریم باید چه کار کنیم. ما به آسانی خطای آنها را برمیداریم و آن را روی خروجی لایه پنهان که آن را با ehidden نامگذاری کردهایم بر میداریم و با تقسیم آن بر روی اتصال های ورودی به هر گره در لایه پنهان ، یعنی اتصال هایی که از لایه ورودی به لایه پنهان آمدهاند به هر اتصال مقدار مناسب را نسبت می دهیم.
تصویر زیر این موضوع را نشان می دهد.
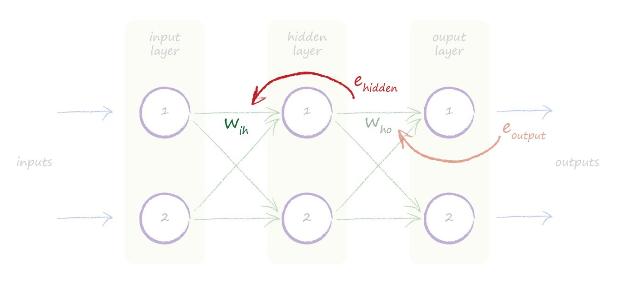
حتی اگر لایههای بیشتری هم داشته باشیم. به توجه به این ایده ما به صورت متناوب از لایه خروجی به عقب روی هر لایه همین کار را تکرار می کنیم. این روش کار و نحوه انجام آن نشان میدهد که چرا به این روش «پخش به عقب» یا «پس انتشار» یا به انگلیسی backpropagation (بک پروپَگیشن) می گویند.
اگر ما از خطای لایه خروجی بر وزن های اتصال های ورودی استفاده کردیم دلیل آن این بود که مقدار هدف در دادههای آموزش به ما داده شده بود. یعنی در دادههای آموزش داریم که مقدار گره اول لایه خروجی میبایست چه مقدار باشد هنگامی که داده اول از مجموعه دادههای آموزش را وارد شبکه می کنیم. بنابراین آن را توانستیم برداریم و برای اصلاح ورودی های اتصال های گره یک لایه خروجی استفاده کنیم. آیا در مورد لایه میانی هم اینو موضوع صحیح است. آیا در دادههای آموزش مقادیر هدف برای گرههای میانی شبکه هم آمده اس؟ این سؤال خوبی است. در دادههای آموزش تنها ورودی و خروجی شبکه مشخص است. هیچ حرفی از مقادیر گرههای میانی به میان نیامده است. به عنوان نمونه در تشخصی دست خط ما ده گره خروجی داریم که نشان دهنده اعداد صفر تا ۹ هستند. اگر تصویر عدد صفر را وارد کنیم گره اول لایه خروجی میبایست مقداری نزدیک به یک را برگرداند و بقیه گرههای خروجی مقادیر کمتری را بر میگردانند. اما صحبتی از مقادیر گرههای لایههای میانی نشده است. پس چطور میتوانیم خطای گرههای میانی را داشته باشیم تا با آن وزن های اتصال های گرههای میانی را اصلاح کنیم در حالی که مقدار هدف مشخصی برای آن تعریف نشده است.
ما مقدار هدف مشخصی برای خروجی هر گره در لایههای میانی نداریم. یک راه حل این است که اتصال های منشعب یک گره در لایه پنهان به گرههای لایه خروجی را برداریم و از خطای هر گره متصل خروجی مقدار مناسبی را به گره پنهان نسبت دهیم. یعنی ترکیبی از خطا های گرههای خروجی را به عنوان خطای گره پنهان در نظر بگیریم. تصویر زیر این ایده را شرح می دهد.
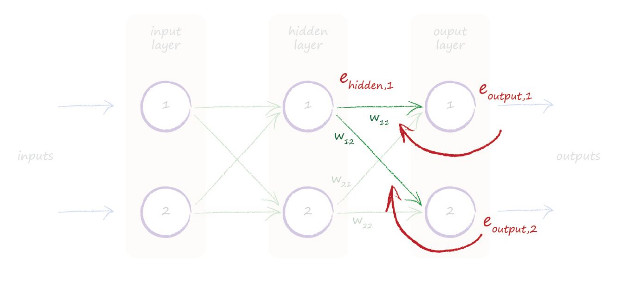
به وضوح دیده میشود که چه اتفاقی افتاد. ولی برای اطمینان بیایید یک بار دیگر موضوع را برای خودمان بنویسیم. ما یک مقدار خطا برای گرههای لایه پنهان نیاز داریم. آن را برای این نیاز داریم که بتوانیم وزن های اتصال های گرهها در این لایه را بروز کنیم. ما این مقدار را ehidden می نامیم. اما ما یک پاسخ واضح نداریم. نمیدانیم مقدار خروجی در این لایه چقدر باید باشد تا با محاسبه تفاوت مقادر واقعی در گره در لایه پنهان با مقدار واقعی مقدار خطا را محاسبه کنیم. دلیل آن این است که در دادههای آموزش ما تنها مقادیر برای گرههای لایههای خروجی آمده است.
ما میتوانیم خطای گرههای خروجی را بر اساس اتصال های مرتبط به گرهها در لایه پنهان نسبت دهیم. بنابراین خطا در گره اول لایه پنهان مجموع خطا های گرههایی متصل شده به آن در لایه خروجی است.
در تصویر بالا، ما یک کسر از خطای خروجی با نام eoutput,1 در اتصال با وزن w11 داریم. همچنین یک کسر از خطای eoutput,2 از گره خروجی دوم در اتصال با وزن w12 داریم.

تصویر بالا به ما کمک کرد که یک ایده ذهنی را عمل ببینیم. تصویر زیر انتشار به عقب خطا ها در یک شبکه سه لایه با مقادیری واقعی را نشان میدهد.
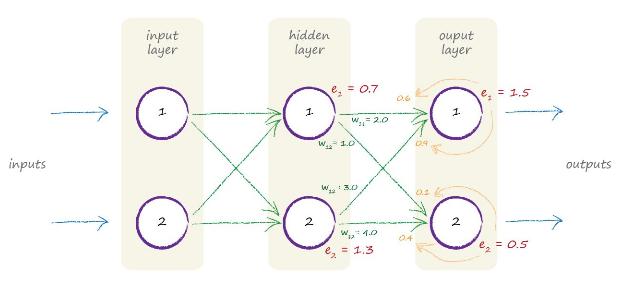
بیایید انتشار یک خطا به عقب را دنبال کنیم . میتوانید ببینید که خطا در گره دوم لایه خروجی 0.5 است.این مقدار خطا به تناسب بین دو اتصال آمده به این گره بر اساس وزن های آنها تقسیم می شود. وزن های اتصال ها برابر 1.0 و 5.0 است بنابراین میزان خطا برای اولی 0.1 و دومی 0.4 است. حدس زدهاید که این مقادیر خطا با مقادیر سایر خطا هایی که از طریق اتصال های دیگر گره به آن رسیده است جمع زده می شود.
تصویر بعدی نشان میدهد که ایده به کار رفته برای انتشار رو به عقب خطا ها بین لایه ها تا اولین لایه ادامه پیدا می کند.
نکتههای کلیدی:
شبکههای عصبی با بهبود وزن های اتصال ها عمل یادگیری را انجام می دهند. مقدار خطا که از تفاوت دادههای آموزشی و خروجی های واقعی شبکه به دست میآید به عنوان راهنمای اصلاح وزن ها استفاده می شود.
مقدار خطا در خروجی به آسانی از تفاوت بین مقدار مورد انتظار و خروجی واقعی محاسبه می شود.
هرچند خطای مرتبط با گرههای داخلی واضح نیست. یک راه رایج برای تقسیم خطا در لایههای خروجی این است که بر اساس انداره وزن های اتصال به یک گره خروجی مقدار خطا را بین گرههای داخلی شبکه تقسیم کنیم.

انیمیشن پیام راشل کوری

Add new comment