شما اینجا هستید
یادگیری وزن ها از بیشتر از یک گره
پیشتر ما یک دسته بندی کننده خطی را با تنظیم شیب در تابع خطی بهبود می دادیم. یعنی بهبود با تنظیم پارامتر شیب تابع خطی در گرهها حاصل می شد. از خطا استفاده می کردیم. به این شکل که تفاوت مقداری که گره ایجاد کرده است و چیزی که میدانستیم باید باشد( در دادههای آموزشی) را محاسبه میکردیم. به عبارتی از مقدار تفاوت بین نتیجه کنونی به دست آمده در گره و مقادیری که نمونههای آزمایشی به ما داده استفاده میکردیم تا نتیجه گره را بهبود دهیم.
این کار خیلی آسان است. دلیل آن این است که رابطه بین خطا و مقدار مورد نیاز برای تغییر شیب خیلی واضح بود.
وقتی بیشتر از یک گره در خروجی مشارکت دارند ،چطور ما وزن های اتصال های مرتبط را بروز میکنیم؟ چطور خطا را محاسبه کنیم و از کجا بفهمیم این خطا را روی کدام یک اعمال کنیم؟
تصویر شبکه زیر مشکل را نشان می دهد:
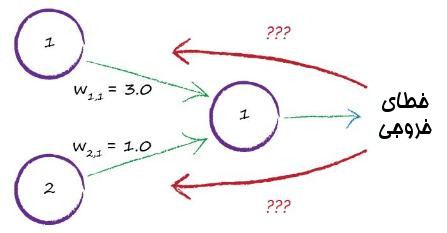
وقتی که ما خروجی را فقط از یک گره میگیریم کارمان خیلی راحتتر است. اگر دو گره داشته باشیم چطور ما از خطای خروجی استفاده می کنیم؟
این بیمعنا است که از کل مقدار خطا برای بروزرسانی فقط یک گره استفاده کنیم. به دلیل اینکه بقیه اتصال ها و وزن های آنها را نادید گرفتیم. مقدار خطای حاصل شده نتیجه مشارکت تمام اتصال ها است.
احتمال خیلی کمی وجود دارد که تنها یک اتصال مسئول کل خطای به وجود آمده باشد. ولی خوب خیلی احتمال کمی است. اگر وزنی را تغییر دهیم که مقدارش درست بوده بدتر می شود. ولی در طی تکرار های بعدی شبکه باز اصلاح می شود.
یک ایده این است که خطا را بر تعداد گرههای مشارکت کننده تقسیم کنیم
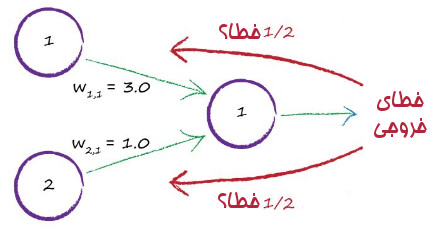
این ایده بدی نیست. هرچند من آن را تا به حال رو یک شبکه عصبی واقعی امتحان نکردم. برای همین مطمئن نیستم که خوب یا بد کار کند.
ایده بعدی این است که خطا را تقسیم کنیم اما نه به اندازه یکسان. به جای آن ما خطا را به اندازه مقدار مشارکت هر اتصال نقسیم کنیم. مقدار مشارکت هر اتصال از از روی وزن اتصال ها محاسبه می کنیم. چرا؟ به دلیل اینکه هر کدام از اتصال ها که بیشتر در حصول این نتیجه مشارکت داشتهاند در حصول این خطا هم بیشتر مشارکت داشته اند. تصویر زیر این ایده را توضیح می دهد.
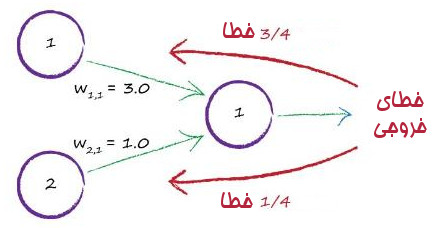
در اینجا دو گره در ایجاد یک خروجی مشارکت داشته اند. وزن خطا ها 3.0 و 1.0 هستند.
اگر ما خطا را به مقدار مرتبط با وزن ها تقسیم کنیم سه چهارم خطای خروجی باید برای بروز رسانی بروزرسانی وزن بزرگتر محاسبه شود. و یک چهارم از مقدار خطا به وزن کوچکتر میرسد
همین ایده را میتوان برای تعداد زیادی از گرهها نیز تکرار کرد. اگر ما 100 گره متصل به یک گره داشته باشیم و خروجی آن گره را محاسبه کنیم، ما خطا را بر اساس صد ارتباط تقسیم می کنیم. به این شکل که بر اساس میزان وزن هر اتصال مقداری از خطا را به آن وزن میدهیم.
همانطور که تا کنون دیدهاید ما از وزن ها در دو جا استفاده می کنیم. اول اینکه ما از وزن ها برای تنظیم قدرت اتصال استفاده می کنیم. این کار را وقتی که سیگنال ها از اتصال های ورودی از یک لایه به یک لایه بعدی در شبکه عصبی در حال ارسال هستند انجام میدهیم. دوم اینکه ما از وزن ها استفاده میکنیم برای اینکه مقدار خطای به دست آماده را به صورت بازگشتی روی اتصال های گرههای شبکه پخش کنیم.
برای همین هم هست که این شیوه با نام «پخش به عقب» یا «پس انتشار» یا به انگلیسی backpropagation (بَک پروپَگِیشِن) معروف است .
اگر یک لایه خروجی دو گره داشته باشد، ما این کار را برای خروجی گره دوم هم انجام می دهیم. گره دوم هم خطای مربوط به خروجی خودش را دارد. که به همان شکل بین اتصال های مرتبط تقسیم می کنیم.
بیایید در ادامه به این موضوع نگاهی بیندازیم.

انیمیشن پیام راشل کوری

دیدگاهها
سلام
دیدگاه جدیدی بگذارید