You are here
گرفتن پیشنهادات
اکنون آماده ایم که پیشنهادات را بر اساس دیکشنری از آیتم های شبیه به هم از میان همه داده ها بگیریم. شما باید همه آیتم هایی که کاربران به آنها امتیاز داده اند را داشته باشید، و از میان آنها آیتم های شبیه به هم را بیابید، و به هر کدام براساس امتیاز هایی که کاربران به آنها داده اند وزن دهید.
دیکشنری آیتم ها می توانند به راحتی برای گرفتن شباهت ها به کار رود.
جدول ۲-۳ فرایند یافتن پیشنهادات به استفاده از شیوه آیتم پایه نشان می دهد. بر خلاف جدول ۲-۲، منتقدین هیچ دخالتی ندارند، به جای آن یک شبکه از فیلم هایی که به آنها رای داده ام در مقابل یک سری که رای نداده ام قرار داده اند.
جدول ۲-۳ سیستم پیشنهادات آیتم پایه برای Toby
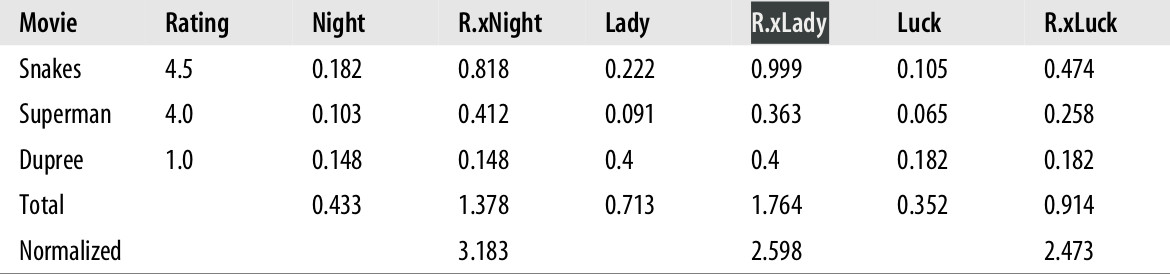
در هر ردیف یک فیلم قرار دارد که ما قبلا دیده ایم، در ادامه امتیازی که من به آنها داده ام.
برای هر فیلمی که دیده ام، یک ستون برای نمایش شباهت آن با فیلمی که دیده ام، است—برای مثال، نرخ شباهت بین superman و The Night Listener برابر 0.103 است. ستون های که با R.x شروع شده اند نمایش دهنده امتیاز من به فیلم ضرب در شباهت آن هست-- وقتی من به Superman رتبه ۴.۰ داده ام، مقدار بعد از Night در ردیف Superman برابر 4.0*0.103 = 0.412 می شود.
ردیف مجموع(Total) نمایش دهنده کل امتیاز های شباهت و کل مقدایر ستون های R.x برای هر فیلم است. برای پیشبینی امتیازی که من هر فیلم خواهم داد، تنها باید مقدار در مجموع را در ستون R.x بر مقدار در ستون مجموع تقسیم کنیم. پیش بینی امتیاز که برای The Night Listener خواهم داد برابر خواهد بود با 1.378/0.433 = 3.183 .
شما می توانید فرایند بالا را با افزودن آخرین تابع مان به recommendations.py محاسبه کنیم:
def getRecommendedItems(prefs,itemMatch,user):
userRatings=prefs[user]
scores={}
totalSim={}
# Loop over items rated by this user
for (item,rating) in userRatings.items( ):
# Loop over items similar to this one
for (similarity,item2) in itemMatch[item]:
# Ignore if this user has already rated this item
if item2 in userRatings: continue
# Weighted sum of rating times similarity
scores.setdefault(item2,0)
scores[item2]+=similarity*rating
# Sum of all the similarities
totalSim.setdefault(item2,0)
totalSim[item2]+=similarity
# Divide each total score by total weighting to get an average
rankings=[(score/totalSim[item],item) for item,score in scores.items( )]
# Return the rankings from highest to lowest
rankings.sort( )
rankings.reverse( )
return rankings شما می توانید این تابع را با مجموعه داده هایی که قبل تر ساختیم برای گرفتن پیشنهادات جدید برای Toby امتحان کنید:
>> reload(recommendations) >> recommendations.getRecommendedItems(recommendations.critics,itemsim,'Toby') [(3.182, 'The Night Listener'), (2.598, 'Just My Luck'), (2.473, 'Lady in the Water')]
The Night Listener هنوز با فاصله زیادی در ابتدا قرار داد، و Just My Luck و Lady in the Water جایشان را عوض کرده اند، گرچه نزدیک به هم هستند. مهم تر از آن، فراخوانی getRecommendedItems مجبور به محاسبه شباهت ها برای تمام رای دهندگان نیست، به خاطر اینکه مجموعه داده ها از قبل آماده شده است.

انیمیشن پیام راشل کوری

Add new comment