You are here
دنبال کردن یک سیگنال در یک شبکه عصبی
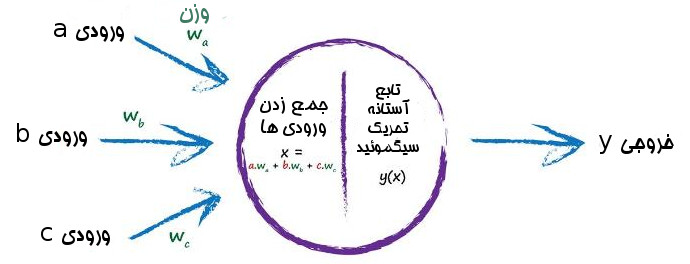
تصویر سه لایه از نورون ها که هر نورون به تمامی نورون های لایه قبلی و بعدی متصل است بسیار الهام بخش است.
اما ایده محاسبه و گذر سیگنال ها از لایه ها برای تبدیل شدن به خروجی به نظر کمی دلهره آور و خیلی سخت باشد.
موافقم که کار سختی است، اما از طرفی خیلی هم مهم است. اینکه بتوانیم شرح دهیم داخل یک شبکه عصبی چه اتفاقی میافتد و چگونه کار میکند خیلی مهم است. هرچند بعداً همه کار را به کامپیوتر میسپاریم.خوب برای اینکه کار سبکتر شود با یک شبکه عصبی کوچکتر کار میکنیم . شبکه عصبی ما از دو لایه تشکیل شده است که در هر لایه دو نورون داریم. به شکل زیر:
بیایید تصور کنیم که ورودی های ما 1.0 و 0.5 هستند. در زیر میبینیم که این ورودی ها وارد شبکه عصبی کوچک ما می شوند.
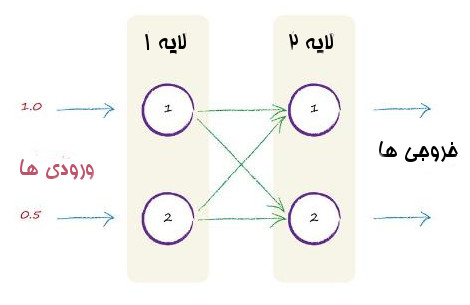
درست مثل قبل، هر گره مجموع ورودی ها را با گذر از تابع فعال سازی به خروجی تبدیل می کند.
ما از تابع سیگموئید که پیشتر دیدیم استفاده می کنیم. در این تابع مقدار x ما برابر با جمع سیگنال های ورودی است و نتیجه یعنی y هر چه شد را به عنوان خروجی نورون بر میگردانیم.
درباره وزن ها چطور؟ سؤال خیلی خوبی است. برای شروع چه مقداری به آنها بدهیم؟ بیایید از وزن های تصادفی استفاده کنیم:
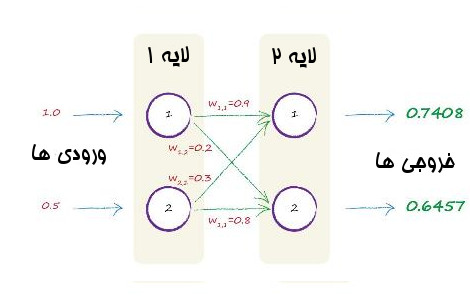
w1,1=0.9
w1,2=0.2
w2,1=0.3
w2,2=0.8
استفاده از اعداد تصادفی ایده بدی نیست. این همان کاری است که پیشتر وقتی میخواستیم شیب اولیه خط را در دسته بندی کننده خطی بدهیم انجام دادیم.همانطور که دیدیم این مقدار تصادفی با ورود هر نمونه به ماشین دسته بندی کننده و یادگیری آن بهبود پیدا می کرد. همین موضوع برای وزن ها در اتصالهای شبکههای عصبی درست است.
تنها چهار وزن در این شبکه عصبی کوچک است. چون کلاً دو تا لایه داریم و در لایه اول هر گره به دو گره بعدی وصل شده اند. تصویر زیر وزن های تصادفی اضافه شده به شبکه را نشان می دهند.
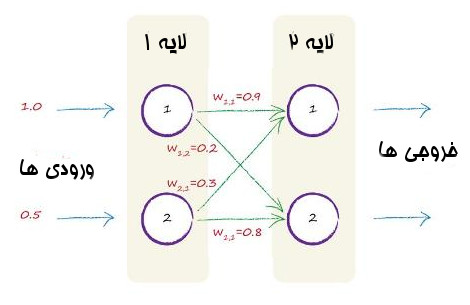
بیایید محاسبه کنیم.
اولین لایه از گرهها لایه ورودی است، و هیچ کاری غیر از ارسال مقدایر سیگنال را انجام نمی دهند. آنها حتی تابع فعال ساز را نیز بر روی سیگنال اعمال نمی کنند. هیچ دلیل خاصی هم نمیخواهد. اولین لایه از شبکه عصبی لایه ورودی است و مقادیر ورودی را نشان می دهد.
خوب با توجه به آنچه گفته شد کار در این لایه راحت است. هیچ محاسبه ای در لایه یک نداریم.
میرسیم به لایه دوم. جایی که محاسبات شروع می شود. برای هر گره در این لایه ما نیاز داریم که ورودی ها را جمع کنیم. همینطور تابع سیگموئید را به خاطر بیاورید.
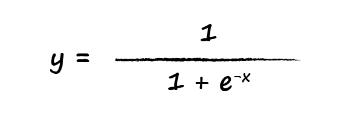
خوب در اینجا مقدار x برابر جمع ورودی های یک گره است. در اینجا ورودی های ما به صورت خام هستند و هیچ پردازش قبلی روی آنها انجام نشده است. اما از وزن های اتصال ها برای تعدیل آنها استفاده می کنیم. تصویر زیر مثل حالت قبل است اما حالا نیاز است که سیگنال های ورودی را با وزن اتصال ها تعدیل کنیم.
خوب بیایید اول بر روی گره یک از لایه دو تمرکز کنیم. هر دو گره لایه اول به آن متصل هستند. مقادیر خام آها هم 1.0 و 0.5 است. وزن اتصال اول 0.9 و وزن اتصال دوم 0.3 است. خوب اول هر عدد خام ورودی را در وزن آن ضرب میکنیم سپس کل آنها را با هم جمع می کنیم.
بنابراین x= ( خروجی گره اول * وزن اتصال) + ( خروجی گره دوم * وزن اتصال)
اگر نخواهیم سیگنال را تعدیل کنیم، فقط یک جمع مقادیر ورودی میماند. یعنی 1.0+0.5اما ما این را نمی خواهیم. در حقیقت وزن ها هستند که در شبکههای عصبی کار یادگیری را انجام می دهند. وزن ها به صورت مداوم بهبود پیدا میکنند تا نتیجهای بهتر و بهتر حاصل شود.
بنابراین ما برای جمع ورودی های تعدیل شده گره اول در لایه دوم داریم x=1.05 .
حالا در اینجا بالاخره میتوانیم خروجی گره را با استفاده از تابع فعال ساز سیگموئید محاسبه کنیم.
خوب برای راحتی از ماشین حساب استفاده کنیم. پاسخ
y=1/(1+0.3499)=1/1.3499
y=0.7408
خیلی عالی شد. ما حالا یک خروجی واقعی از یکی از گرههای لایه دوم داریم.
بیایید بر روی گره دوم از لایه دوم نیز محاسبه را انجام دهیم و جمع ورودی های تعدیل شده را محاسبه کنیم.
مقدار x برابر است با:
(خروجی گره اول * وزن گره) + ( خروجی گره دوم * وزن گره)
یعنی
x=(1.0*0.2)+(0.5*0.8)
x=0.2+0.4
x=0.6
خوب حالا که مقدار x را داریم میتوانیم برای محاسبه خروجی گره دوم تابع فعال ساز سیگومئید را روی آن پیاده کنیم
y=1/(1+0.5488)=1/(1.5488)
y=0.6457
تصویر زیر خروجی های محاسبه شده شبکه را نشان می دهد:
خوب محاسبه فقط دو خروجی از یک شبکه ساده شده مقداری کار برد. ما نمیخواهیم برای شبکههای بزرگتر محاسبات را با دست انجام دهیم. خوشبختانه کامپیوتر ها خیلی خوب این کار را انجام میدهند. میتوانید میلیونها از این دست محاسبات را به آنها بدهید تا انجام دهند بدون اینکه خسته شوند.
با این حال، حتی نمیخواهیم دستور العمل محاسبات به کامپیوتر بدهیم. اینکه بخواهیم برای شبکههایی با دو لایه یا ۴ یا ۸ یا حتی صد ها گره در هر لایه را بنویسیم خستهکننده است.همچنین احتمال خطا را برای نوشتن این همه دستورالعمل برای این همه گره و لایه خیلی زیاد می شود. هرگز محاسبه ها را دستی انجام نمی دهیم.
خوشبختانه ریاضیات با راه حلهای کوتاه تری برای گرفتن خروجی از شبکههای عصبی به ما کمک می کند. حتی وقتی تعداد لایه ها و گرهها خیلی زیاد می شود. این مختصر کردن محاسبات تنها برای خوانندهها خوب نیست. برای خود کامپیوتر ها هم خوب است. به خاطر اینکه دستورالعمل ها خیلی کوتاهتر میشوند و بهینهتر روی کامپیوتر ها انجام میگردند و سرعت اجرا نیز بیشتر می شود. این رویکرد از ماتریس ها استفاده میکند که در ادامه به آن نگاهی خواهیم داشت.

انیمیشن پیام راشل کوری

Add new comment